Loi de fiabilité
La préoccupation principale de la fiabilité est de prédire la probabilité d'occurrence d'une défaillance d'un système (panne). Ceci se fait en établissant une loi de fiabilité.

Cet article ne cite pas suffisamment ses sources ().
Si vous disposez d'ouvrages ou d'articles de référence ou si vous connaissez des sites web de qualité traitant du thème abordé ici, merci de compléter l'article en donnant les références utiles à sa vérifiabilité et en les liant à la section « Notes et références ».
En pratique : Quelles sources sont attendues ? Comment ajouter mes sources ?
Données de fiabilité modifier
Fonctions de mortalité et de survie modifier
Lorsque les dates de défaillances sont connues avec précision modifier
Une entreprise met sur le marché N systèmes à l'instant 0 ; nous supposons que ces systèmes ne sont soumis à aucune réparation. On enregistre les moments de première panne ti : {t1, t2…, tn} que nous supposons classés par ordre croissant. L'indice i est appelé « rang », puisque c'est l'indice d'une suite. Le terme « moment » peut désigner une durée de fonctionnement — en général exprimée heures, jours ou années —, mais aussi un nombre de tours pour une machine tournante, un nombre de cycles pour un système fonctionnant par cycles…
À chaque instant t, on peut déterminer la proportion de systèmes ayant connu une défaillance : c'est la « mortalité », notée F :

ou, de manière indicée, puisque les ti sont classés par ordre croissant
- , où N est la taille de l'échantillon observé.

La quantité i = card{tj ≤ t} — nombre de systèmes ayant connu une défaillance avant t (voir Cardinal (mathématiques)) — est appelée « nombre de défaillances cumulé » ; F est aussi appelé « fréquence cumulée ». La mortalité F part de 0 — on considère que tous les systèmes sont en fonctionnement à la mise en service — et atteint 1 (ou 100 %) au bout d'un certain temps — les systèmes ne sont pas éternels et finissent tous par défaillir un jour. Cette fonction F correspond statistiquement à une fonction de répartition.
On définit également la fonction complémentaire, appelée « fiabilité » ou « survie », et notée R (reliability) :
- R(t) = 1 - F(t)
- Ri = 1 - Fi
C'est en général cette fonction R que l'on considère : elle permet une présentation plus positive de la fiabilité (on parle de ce qui marche plutôt que de ce qui ne marche pas). D'un point de vue mathématiques, F est plus pertinente puisque c'est une fonction de répartition. Dans l'analyse des systèmes complexes, R est plus pertinent dans le cas des associations série, et F est plus pertinent dans le cas des associations parallèles (redondances), voir Schémas fonctionnels de fiabilité. Dans le cas d'un système suivant une loi exponentielle ou de Weibull — des situations très fréquentes —, l'expression de la loi de survie R est plus simple que celle de la loi de mortalité F.
Les instants de survenue des défaillances ti sont des variables aléatoires. De fait, R (et F) sont également des variables aléatoires, il faut donc corriger les fréquences cumulées, par des formules issues de la loi binomiale.
| Taille de l'échantillon | Formule | Fréquence cumulée |
|---|---|---|
| N ≤ 20 | formule des rangs médians | |
| 20 ≤ N ≤ 50 | formule des rangs moyens | |
| N ≥ 50 | formule des modes |









On peut par ailleurs définir un intervalle de confiance, pour un risque α bilatéral donné (niveau de confiance bilatéral 1 - α), avec la loi de Fisher, Qp(ν1, ν2) étant le quantile d'ordre p de la loi de Fisher :
- limite inférieure : , avec
- ν1 = 2(N - i + 1)
- ν2 = 2i
- limite supérieure : , avec
- ν1 = 2(i + 1)
- ν2 = 2(N - i)


Avec des données censurées modifier
On ne connaît pas toujours l'instant de survenue exacte d'une défaillance ; on a parfois le nombre de défaillances survenues durant un intervalle de temps (censure par intervalle). Par exemple, si un système est suivi pendant plusieurs années, on enregistre le nombre de défaillances chaque mois. Ainsi, à l'instant ti, on a le nombre nj de défaillances survenues dans les intervalles ]tj - 1 ; tj]. On a alors

éventuellement corrigé par une formule des rangs.
La méthode présentée ci-dessus convient également lorsque l'on arrête l'observation à un moment donné, alors que certains systèmes sont encore en service : c'est un cas de censure à droite, mais pour lequel on n'a aucune donnée après la date de censure.
Par contre, cette méthode ne convient pas lorsque l'on a des censures à gauche ou bien des censures à droite mais avec des dates de défaillance ultérieures ; par exemple, si un système est arrêté ou bien subit une maintenance avant défaillance pour une raison quelconque. Dans ces cas-là, on utilise des méthodes qui calculent une probabilité Pi de défaillance sur un intervalle i, puis en déduisent une fiabilité Ri.
On utilise principalement la méthode de Kaplan-Meier, la méthode actuarielle et la méthode de Turnbull, et plus rarement la méthode de Wayne-Nelson et la méthode du rang corrigé de Herd-Johnson. Si l'on n'a pas de censure, on retrouve en général la formule des rangs moyens ou bien des modes.
Densité de défaillance modifier
On définit la densité de défaillance comme le taux de variation de la fonction de mortalité F. C'est la « vitesse de mortalité » :

ou encore :

Si n(t) est le nombre de défaillances cumulées à l'instant t (nombre de défaillances entre 0 et t), on a alors

et donc
- .

Avec la notation indicée, on a :
- .

Notez bien la différence entre ni, qui est le nombre de défaillances entre ti et ti + 1, et n(t) qui est le nombre de défaillances entre 0 et t.
Taux de défaillance modifier
On définit le taux de défaillance λ (lettre grecque lambda) sur un intervalle ]t, t + Δt] comme étant l'opposé du taux de variation relatif de la survie :

C'est donc le rapport entre le nombre de défaillances dans cet intervalle sur le nombre de systèmes restants au début de l'intervalle, divisé par la durée de l'intervalle. C'est un nombre positif. On a :

ou, de manière indicée

Que signifient concrètement ces grandeurs ? modifier
- Pour une population de N systèmes
- R(t) est la proportion de systèmes encore en service à l'instant t. C'est la proportion de systèmes dont la durée de vie T est supérieure à t.
- N·R(t) est le nombre de tels systèmes.
- F(t) est la proportion de systèmes ayant connu une défaillance avant l'instant t. C'est la proportion de systèmes dont la durée de vie T est inférieure ou égale à t.
- N·F(t) est le nombre de tels systèmes.
- ƒ(t)·Δt est la proportion de systèmes qui connaîtront une défaillance dans l'intervalle ]t ; t + Δt]. C'est la proportion de systèmes dont la durée de vie T est dans ]t ; t + Δt].
- N·ƒ(t).Δt est le nombre de tels systèmes.
- λ(t)·Δt est la proportion qui connaîtront une défaillance dans l'intervalle ]t ; t + Δt] parmi les systèmes encore en service à l'instant t. C'est la proportion, parmi les systèmes ayant une durée de vie supérieure à t, des systèmes dont la durée de vie T est dans ]t ; t + Δt].
- N·R(t)·λ(t)·Δt est le nombre de tels systèmes.
- Pour un système donné
- R(t) est la probabilité d'être encore en service à l'instant t. C'est la probabilité d'avoir une durée de vie T supérieure à t
- R(t) = P(T > t).
- F(t) est la probabilité d'avoir eu une défaillance avant l'instant t. C'est la probabilité d'avoir une durée de vie T inférieure ou égale à t :
- F(t) = P(T ≤ t).
- ƒ(t)·Δt est la probabilité d'avoir une défaillance dans l'intervalle ]t ; t + Δt]. C'est la probabilité d'avoir une durée de vie T dans ]t ; t + Δt]
- ƒ(t)·Δt = P(T ∈ ]t ; t + Δt]).
- λ(t)·Δt est la probabilité, si le système est encore en service à l'instant t, de connaître une défaillance dans l'intervalle ]t ; t + Δt] (probabilité conditionnelle). C'est la probabilité, si le système a une durée de vie supérieure à t, d'avoir une durée de vie T est dans ]t ; t + Δt].
- λ(t)·Δt = P(T ∈ ]t ; t + Δt] | T > t).
La différence entre la densité ƒ et le taux λ peut être difficile à appréhender. Disons qu'au moment où l'on met un système en service, on sait qu'après une durée d'utilisation t dans le futur, il aura une probabilité ƒ de tomber en panne[1]. Si maintenant on considère un système ayant déjà été utilisé pendant une durée t, on sait qu'il a une probabilité λ de défaillir maintenant[2].
Collecte des données modifier
Le point critique est en général la collecte des données.
Le cas le plus simple est celui d'un industriel suivant son parc de machines : il demande à son équipe de maintenance d'enregistrer les défaillances. Dans le cas d'un fabricant qui voudrait évaluer les produits vendus, le problème est plus délicat. Les constructeurs automobiles imposent en général que la maintenance soit faite dans un garage de leur réseau sous peine d'annulation de la garantie, ce qui permet d'obtenir les statistiques pendant cette durée ; le problème est alors que l'on ne sait pas de quelle manière le produit a été utilisé (conduite souple ou nerveuse, autoroute ou ville), on ne connaît que la date de mise en service et le kilométrage.
Mais un fabricant peut aussi vouloir évaluer la loi de survie avant la mise sur le marché, pour pouvoir dimensionner la durée de garantie et conseiller une date de maintenance/révision. Pour cela, il peut effectuer des essais de fiabilité. L'essai doit reproduire l'utilisation réelle du produit, ce qui implique de définir un « profil de mission », c'est-à-dire un mode d'utilisation de référence (type de conduite pour un véhicule, cadence de production et réglages pour une machine industrielle, …).
Un point important consiste, lorsque c'est possible, de distinguer les différents modes de défaillance. En effet, chaque mode de défaillance suit sa propre statistique de mortalité/survie, et l'on peut voir le comportement d'un système complexe comme la composition de chacun des modes. Selon le niveau de détail visé, on peut séparer les données pour chaque organe (sous-système), ou pour un sous-système donné, les différents modes de défaillance — par exemple, pour une pièce mécanique, distinguer l'usure de la rupture en fatigue.
Exemple modifier


Une entreprise de chemins de fer qui suit l'instant de première panne d'un échantillon de 28 locotracteurs durant un an, date à laquelle a lieu leur première révision. Les durée de service avant la première panne sont donnés en jour et sont, par ordre croissant : {2, 5, 9, 13, 17, 22, 27, 39, 39, 39, 52, 64, 64, 76, 86, 97, 108, 121, 135, 151, 169, 191, 215, 245, 282, 332, > 365, > 365}. On a N = 28, on utilise donc la formule des rangs moyens.
On remarque que deux des locotracteurs n'ont pas subi de défaillance avant leur première révision ; c'est un cas de censure à droite. Ces deux cas ne permettent pas de « placer des points » sur la courbe, mais entrent néanmoins dans la statistique, puisqu'il font partie de l'effectif total N. On utilise dans un premier temps la méthode des rangs.
| Nombre cumulé de défaillances i |
Instant de défaillance ti (j) |
Fréquence cumulée (mortalité) F |
Fiabilité (survie) R |
Taux de défaillance λ (j−1) |
|---|---|---|---|---|
| 1 | 2 | 0,034 5 | 0,966 | 0,012 3 |
| 2 | 5 | 0,069 0 | 0,931 | 0,009 62 |
| 3 | 9 | 0,103 | 0,897 | 0,010 0 |
| 4 | 13 | 0,138 | 0,862 | 0,010 4 |
| 5 | 17 | 0,172 | 0,828 | 0,008 70 |
| 6 | 22 | 0,207 | 0,793 | 0,009 09 |
| 7 | 27 | 0,241 | 0,759 | 0,011 9 |
| 10 | 39 | 0,345 | 0,655 | 0,004 27 |
| 11 | 52 | 0,379 | 0,621 | 0,009 80 |
| … | ||||
| Nombre cumulé de défaillances i |
Instant de défaillance ti (j) |
Fi min | Fi | Fi max |
|---|---|---|---|---|
| 1 | 2 | 0,002 | 0,034 5 | 0,07 |
| 2 | 5 | 0,01 | 0,069 0 | 0,1 |
| 3 | 9 | 0,03 | 0,103 | 0,11 |
| 4 | 13 | 0,05 | 0,138 | 0,2 |
| 5 | 17 | 0,07 | 0,172 | 0,3 |
| 6 | 22 | 0,1 | 0,207 | 0,3 |
| 7 | 27 | 0,1 | 0,241 | 0,4 |
| 10 | 39 | 0,2 | 0,345 | 0,4 |
| 11 | 52 | 0,2 | 0,379 | 0,5 |
| … | ||||

Reprenons l'exemple avec la méthode de Kaplan-Meier.
Pour chaque date de défaillance ti, nous déterminons :
- le nombre Ni de systèmes encore en fonctionnement avant ti (ni défaillants, ni censurés) ;
- le nombre Di de systèmes défaillant durant la journée ti ;
et l'on en déduit Pi la probabilité conditionnelle de défaillance durant la journée ti :
- Pi = Di/Ni
et la fiabilité Ri à l'instant ti :
- .

Les censures sont donc prises en compte par les Ni.
| Instant de défaillance ti (j) |
Nombre de systèmes en fonctionnement Ni |
Nombre de systèmes défaillants Di |
Probabilité conditionnelle de défaillance Pi |
Fiabilité (survie) Ri |
|---|---|---|---|---|
| 2 | 28 | 1 | 0,035 7 | 0,964 |
| 5 | 27 | 1 | 0,037 0 | 0,929 |
| 9 | 26 | 1 | 0,038 5 | 0,893 |
| 13 | 25 | 1 | 0,04 | 0,857 |
| 17 | 24 | 1 | 0,041 7 | 0,821 |
| 22 | 23 | 1 | 0,043 5 | 0,786 |
| 27 | 22 | 1 | 0,045 5 | 0,75 |
| 39 | 21 | 3 | 0,143 | 0,643 |
| 52 | 18 | 1 | 0,055 6 | 0,607 |
| … | ||||

La méthode actuarielle, elle, consiste à découper la période de surveillance en tronçons d'égale durée. Par rapport à la méthode de Kaplan-Meier, on peut donc avoir des censures au cours d'un tronçon. Lorsqu'on se réfère à une date ti, on dénombre les défaillances Di et les censures Ci sur l'intervalle précédant ti, c'est-à-dire [ti - 1 ; ti[. On a donc

et toujours
- .
On considère arbitrairement que sur les Ci systèmes censurés, la moitié aurait présenté une défaillance.
Elle demande moins de calculs que la méthode de Kaplan-Meier, mais en revanche n'utilise pas toute l'information (elle cumule les dates sur une période) et n'est donc précise que pour les grands échantillons. Elle ne s'applique que lorsque l'on a un grand nombre de données, typiquement au moins 30 ou 50 — ce n'est pas le cas de notre exemple, mais nous allons tout de même l'utiliser. Le nombre de classes — le nombre d'intervalles de temps — est typiquement la racine carrée de la taille de l'échantillon. Ici, nous choisissons arbitrairement une durée de deux semaines (quatorze jours).
| Instant de référence ti (j) |
Classe [ti ; ti + 1[ |
Nombre de systèmes en fonctionnement Ni |
Nombre de systèmes défaillants Di |
Nombre de systèmes censurés Ci |
Probabilité conditionnelle de défaillance Pi |
Fiabilité (survie) Ri |
|---|---|---|---|---|---|---|
| 0 | [0 ; 14[ | 28 | 4 | 0 | 0,143 | 1 |
| 14 | [14 ; 28[ | 24 | 3 | 0 | 0,125 | 0,857 |
| 28 | [28 ; 42[ | 21 | 3 | 0 | 0,143 | 0,75 |
| 42 | [42 ; 56[ | 18 | 1 | 0 | 0,0556 | 0,643 |
| 56 | [56 ; 70[ | 17 | 2 | 0 | 0,118 | 0,607 |
| … | ||||||
Profils typiques modifier
D'un point de vue phénoménologique, le taux de défaillance instantané λ nous renseigne sur le comportement du système :
- un λ décroissant indique que le taux de panne diminue avec le temps ; on désigne cela par la « mortalité infantile » ou « juvénile » ; c'est typiquement la défaillance de systèmes ayant des « défauts de jeunesse » ou des non-qualités, ou bien des systèmes en rodage ;
- un λ constant indique un système « sans mémoire » : le taux de défaillance est constant, la probabilité de défaillance d'un système donné est uniforme dans le temps, il n'y a pas d'usure ; on parle parfois de panne « purement aléatoire » ;
- un λ croissant : le taux de défaillance augmente avec le temps, indiquant un phénomène de vieillissement, d'usure.
Notons que dans tous les cas, R est décroissant, même si le taux de défaillance décroît.
Nous représentons ci-dessous des courbes pour les trois cas, avec à chaque fois quatre graphiques :
- en haut à gauche, les courbes de survie et de mortalité ;
- en bas à gauche, la fonction de densité de la loi de fiabilité (probabilité de défaillance instantanée) ;
- en haut à droite, le taux de défaillance instantané λ en fonction du temps ;
- en bas à droite, la courbe de survie dans un graphique de Weibull, ln(-ln(R)) en fonction de ln(t), voir Loi de Weibull > Détermination des paramètres de la loi.
-
 λ décroissant
λ décroissant -
 λ constant
λ constant -
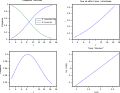 λ croissant
λ croissant



Pour revenir sur la différence entre la densité ƒ et le taux λ :
- on voit que quand λ est uniformément décroissant ou constant, ƒ est décroissant ;
- quand λ est uniformément croissant, ƒ présente un pic, les systèmes ont donc tendance à tous tomber en panne en même temps.

Dans le cas des systèmes électroniques, on a souvent une courbe de taux de défaillance λ en trois parties (courbe en haut à droite dans la figure ci-contre) : λ décroissant (défaillance des systèmes défectueux), puis λ constant (défaillance aléatoire, la majeure partie de la courbe), puis λ croissant (vieillissement sur la fin). On parle de courbe en « baignoire » (bathtube shaped curve).

Dans le cas des systèmes mécaniques, on a une courbe de taux de défaillance λ en deux parties : λ décroissants (rodage) puis λ croissants (usure), donnant une courbe globalement parabolique.
Notons que si l'on tourne la courbe de survie d'un quart de tour vers la gauche, on obtient une pyramide des âges exprimée en proportion de la population totale.
Indicateurs de fiabilité modifier
À partir de ces données, on peut définir un certain nombre d'indicateurs de fiabilité. En particulier, on peut définir le temps moyen de fonctionnement avant panne, ou MTTF (mean time to failure) :

si l'on connaît les instants exacts de chaque défaillance, ou bien

en cas de censure par intervalle.
On détermine aussi la durée de vie d'espérance x %, notée Lx ou Bx, c'est-à-dire la durée au bout de laquelle on a x % de défaillance et donc 100 - x % de survie. Par exemple :
- L10, ou B10, est la durée au bout de laquelle il reste 90 % des systèmes en fonctionnement (10 % de défaillance).
- L50, ou B50, est la durée au bout de laquelle il reste 50 % des systèmes en fonctionnement (50 % de défaillance), donc la médiane de la durée de vie.
Nous ne considérons ici que les instants de première défaillance. D'autres indicateurs utiles sont définis lorsque l'on considère a réparation des systèmes, et donc la durée entre deux pannes ainsi que le temps de réparation.
Exemple
Dans l'exemple précédent, on ne peut pas calculer le MTTF exact puisqu'il manque deux données. Toutefois, on peut estimer un MTTF minimal on considérant que les deux locotracteurs censurés ont eue une défaillance à 365 j. On trouve
- MTTF ≥ 119 j.
Par ailleurs, avec un échantillon de 28 locotracteur, L10 est la durée au bout de laquelle on a 3 défaillances (3 ≈ 28/10) soit
- L10 ≈ 9 j
La médiane sépare l'échantillon en deux parts de 14 systèmes, donc se situe entre t14 = 76 j et t15 = 86 j ; par convention, on prend le milieu, soit
- L50 ≈ 81 j
Analyse non-paramétrique modifier
Une analyse non-paramétrique est une analyse ne faisant pas intervenir de loi. Ces méthodes consistent essentiellement à construire des courbes de survie « en escalier » (avec une marche à chaque défaillance constatée), avec les méthodes présentées ci-dessus (méthode des rangs, méthode avec censure). On peut en extraire des données caractéristiques mentionnées ci-dessus — médiane de survie (50 % des systèmes connaissent une défaillance avant ce moment, 50 % après) ou d'autres quantiles (comme le premier décile, L10), le MTTF, le taux de défaillance à un moment donné…
L'avantage est que l'on ne présuppose pas de distribution ; par extension, on peut travailler sur des données qu'aucune distribution ne décrit de manière satisfaisante. L'inconvénient est que l'on a une précision plus faible (un intervalle de confiance plus large), et que l'on ne peut pas faire de prédiction ni d'extrapolation.
Exemple
Nous avons construit les courbes pour l'exemple des locotracteurs. Nous pouvons en déduire que l'on a
- un L10 de 9 j,
- une médiane L50 à 81 j,
- un MTTF supérieur à 119 j,
- et un taux de défaillance λ globalement décroissant, ce qui indique que l'on est encore dans les pannes « de jeunesse » et pas encore dans l'usure.
Analyse paramétrique modifier
Dans un certain nombre de cas, on peut utiliser une loi statistique pour décrire les données. Les paramètres de cette loi sont ajustés aux données par régression ou bien par maximum de vraisemblance, à partir des valeurs numériques de fiabilité R établies (par la méthode des rangs ou une méthode avec censure).
L'avantage par rapport à une analyse non-paramétrique est que l'on a une bien meilleure précision (un intervalle de confiance plus restreint). L'inconvénient est qu'il faut avoir à disposition une loi décrivant bien les données, ce qui n'est pas toujours le cas, ainsi que de moyens informatiques pour effectuer les calculs.
En général, on utilise une loi continue. Nous avons dit précédemment que F était une fonction de distribution. La fonction F est en général dérivable, ce qui permet de définir la fonction de densité ƒ :

et le taux de défaillance instantané
- .

On peut utiliser n'importe quelle loi statistique pourvu qu'elle décrive les données, et qu'elle ait si possible un « sens physique ». Dans la pratique, on retient en général quatre lois :
- la loi exponentielle ;
- la loi normale ;
- la loi log-normale ;
- la loi de Weibull.
On rencontre aussi plus rarement la loi du χ², de la plus petite ou plus grande valeur extrême, de Poisson, binomiale, logistique ou log-logistique.
Pour les problèmes de fatigue, on utilise des lois dédiées : loi de Wöhler, loi de Basquin, loi de Bastenaire.
La loi de Weibull est souvent utilisée car :
- elle est à valeurs positives, contrairement à la loi normale par exemple, or seules les valeurs positives d'âge ont du sens (on ne considère pas des défaillances avant mise en service) ;
- elle permet de simuler de nombreux profils différents, en particulier
- λ décroissants pour β < 1,
- λ constants — loi exponentielle — pour β = 1,
- λ croissants pour β > 1,
- elle s'approche d'une loi normale pour 3 ≤ β ≤ 4 ;
- on peut facilement déterminer ses caractéristiques à partir d'un diagramme de Weibull/Allen Plait ;
- on en extrait facilement le taux de défaillance λ.
Exemple


Reprenons l'exemple des locotracteurs ci-dessus. Nous testons plusieurs modèles :
- le modèle exponentiel : la fiabilité est de la forme
R(t) = e-λt, soit
ln(R) = -λt
donc en traçant le diagramme (t, ln R), on doit obtenir une droite passant par 0 et de pente -λ, ce qui nous donne le paramètre de la loi ; - le modèle normal : on trace la droite de Henry, qui permet d'obtenir les paramètres μ (espérance) et σ (écart type) de la loi ;
- le modèle log-normal : on trace également une droite de Henry, en utilisant les quantiles de la loi log-normale ;
- le modèle de Weibull : on trace un diagramme de Weibull (ou diagramme d'Allen Plait) (ln t, ln(-ln R)), qui permet d'obtenir une droite ; la pente et l'ordonnée à l'origine de la droite nous donnent les paramètres β (forme) et λ (échelle) de la loi.
Les droites sont obtenues par régression linéaire. On voit graphiquement que c'est le modèle de Weibull qui colle le mieux, avec :
- β ≈ 0,8 ;
- λ ≈ 125.
On a bien un taux de défaillance décroissant (β < 1). À partir de ces paramètres, on peut en déduire le MTTF, qui est l'espérance de la loi :

ainsi que sa médiane et sa durée de vie d'espérance 10 %
- .
- L10 ≈ 8 j






| Modèle | MTTF | L10 | L50 |
|---|---|---|---|
| Non-paramétrique (rangs médians) |
≥ 119 j | 9 j | 81 j |
| Paramétrique (loi de Weibull) |
142 j | 8 j | 79 j |
Si le modèle paramétrique est pertinent, il vaut mieux retenir les résultats du modèle paramétrique. Mais il est toujours utile de déterminer les mêmes indicateurs avec une méthode non-paramétrique pour vérifier la cohérence des résultats.
Notons qu'ici nous avons effectué des régressions linéaires sur des diagrammes particuliers (diagramme semi-logarithmique, droite de Henry, diagramme d'Allen Plait). Cette méthode permet de faire les calculs « à la main », mais ne permet pas de comparer quantitativement les résultats. Nous pouvons également effectuer une régression non linéaire sur les données brutes (par la méthode des moindres carrés ou bien le maximum de vraisemblance), ce qui permet de comparer les résidus. On peut toutefois commencer par les régressions linéaires pour partir d'une solution approchée, et donc faciliter la convergence et diminuer le nombre d'étapes de régression.
| Loi | Régression linéaire |
Régression des moindres carrés |
S |
|---|---|---|---|
| Exponentielle | λ = 0,007 36 | λ = 0,008 22 | 0,025 2 |
| Normale | μ = 117 σ = 120 |
μ = 99,1 σ = 104 |
0,114 |
| Log-normale | μ = 4,21 σ = 1,62 |
μ = 4,30 σ = 1,43 |
0,012 6 |
| Weibull | β = 0,825 λ = 124,7 |
β = 0,827 λ = 124,5 |
0,001 03 |
Le tableau ci-dessus compare les valeurs des paramètres obtenus avec une régression linéaire sur un diagramme adapté, et celles obtenues par régression des moindres carrés (non-linéaire). Nous constatons que la somme des carrés des résidus, S, est la plus faible pour la loi de Weibull.
Approximation par une loi exponentielle modifier
Dans un certain nombre de cas, et en particulier lorsque l'on manque d'informations permettant d'utiliser un modèle plus pertinent, on fait l'approximation que l'on a une loi exponentielle. En effet, en général, le taux de défaillance instantané λ est stable — la loi exponentielle est donc pertinente — ou croissant. Dans ce dernier cas, la loi exponentielle prédit une mortalité plus importante que la réalité « dans les premiers instants », ce qui va dans le sens de la prudence (approche dite « conservative »). Cette approximation n'est en revanche pas pertinente si l'on a un λ décroissant ; on voit d'ailleurs dans l'exemple des locotracteurs que la courbe exponentielle est au-dessus des points expérimentaux jusqu'à environ t = 200 j.
Le fait d'utiliser une loi exponentielle facilite les calculs, en particulier lorsque l'on prend en compte des systèmes complexes (voir Schéma fonctionnel de fiabilité).
Certains documents donnent un taux de défaillance λ, sous la forme d'une valeur unique, même lorsque ce taux n'est pas constant. Il s'agit là d'une approximation tacite par une loi exponentielle. Certains documents sont plus « honnêtes » et donnent un taux de défaillance λ pour une durée de vie donnée. Cela équivaut à faire une approximation exponentielle « autour d'un point », à l'instar d'un développement limité.
Voir aussi modifier
Articles connexes modifier
Notes et références modifier
- ou pour être exact : une probabilité ƒ(t)·Δt de tomber en panne dans la période [t ; t + Δt]
- ou plus exactement : une probabilité λ(t)·Δt de défaillir dans la durée Δt qui suit